Using raw hemato-analyzer data to improve diagnostics of hematopoietic disorders: opportunities and challenges
When generating a routine complete blood count (CBC), modern hemato-analyzers produce hundreds of additional advanced parameters such as cell size, complexity and fluorescence markers that reflect subtle changes in cell morphology and maturation. These extensive parameters could potentially be used to aid in the diagnosis of hematopoietic disorders. For example, pediatric syndromes such as MDS-RCC and SAA both present with multilineage cytopenias and hypocellular bone marrow, yet the underlying pathophysiology and optimal treatment for MDS-RCC and SAA are different. Advanced parameters may provide additional markers to help differentiate such conditions. However, these raw data need rigorous preprocessing and an intricate data analytic approach before they can be used in scientific research projects.
We hypothesize that AI-supported data analytic pipelines of routine hemato-analyzer data may support the diagnostic trajectory of MDS and other hematopoietic disorders. The objective of this study was therefore to explore the potential of raw hemato-analyzer data for improving diagnostics of hematopoietic disorders. Here, we describe our initial data cleaning and analysis of these hemato-analyzer data, including opportunities and challenges.
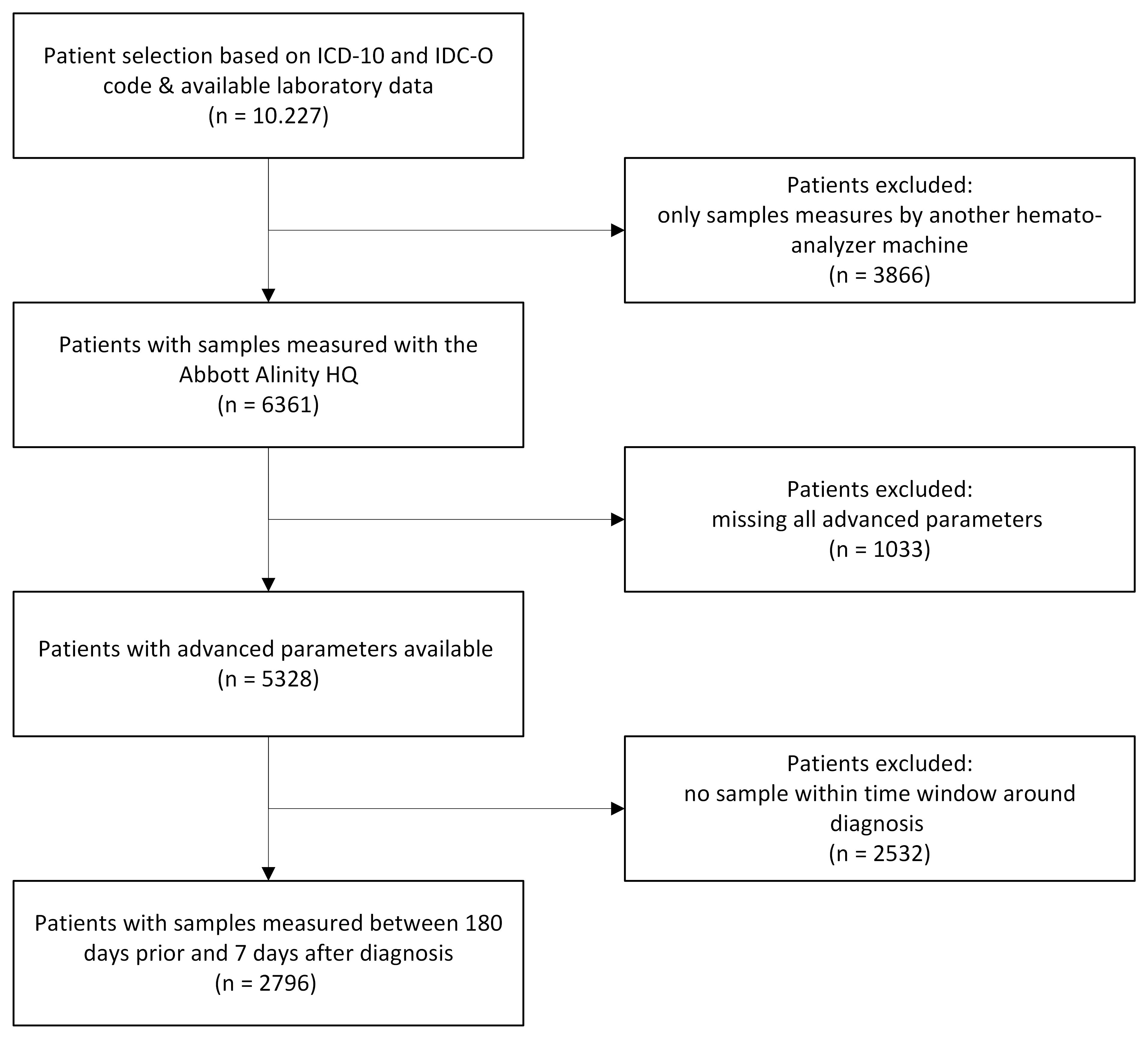
We performed a retrospective study using routine laboratory data from the Utrecht Patient Oriented Database (UPOD). We included all patients diagnosed with hematopoietic or hemato-oncological disorders (based on assigned ICD-10 and ICD-O codes) between 2007 and May 2025 and their raw hemato-analyzer data from the Abbott Alinity hq analyzers. Data analysis was performed in Python (v3.13.1). We excluded the records in preprocessing where advanced parameters were missing and filtered the data on samples which were obtained prior to the diagnostic time point (-180 until +7 days).
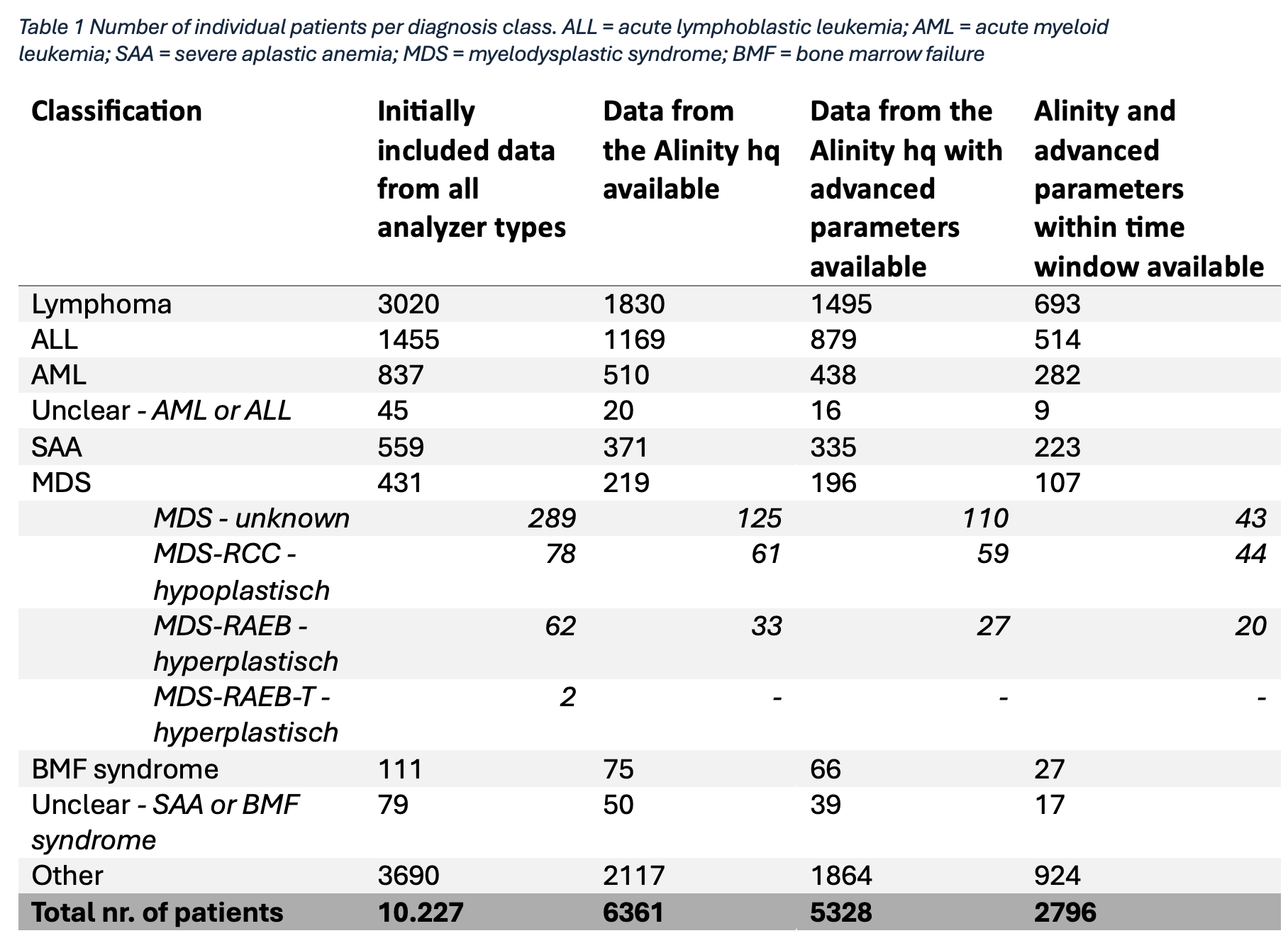
A total of 10.227 individual patients with 260 distinct assigned diagnoses were included (Figure 1). Assignment of diagnoses yielded several complexities, including overlapping diagnostic labels, patients with multiple or sequential diagnoses, and uncertainty regarding the exact diagnose time point. These issues were discussed in a multidisciplinary team, resulting in a final classification into seven diagnostic groups (Table 1). Preprocessing steps consecutively excluded 4899 patients due to missingness or use of a different analyzer, and 2532 patients because of the time window, leaving 2796 individuals for analysis (Figure 1).
Our multi-step filtering process ensured a fit-for-purpose dataset of raw hemato-analyzer data suitable for exploratory data clustering and biomarker discovery to improve diagnostics of hematopoietic disorders. Currently, the use of routine care data is hampered by vendor- and machine type-specific preprocessing requirements of hemato-analyzer data and department and healthcare professional-specific preprocessing requirements for diagnosis data. Only through interdisciplinary collaboration between healthcare professionals, laboratory specialists, data scientists and researchers, we can leverage the potential of routine care data to gain new diagnostic insights and feed them back into clinical care.